

为《大数据基础》这一课程的课程设计,在此进行存档。
1. 摘要
本项目旨在构建一种面向植物幼苗图像分类任务的高性能深度学习模型。基于改进的 YOLO11m-cls 架构,融合 StripBlock[1] 和 Convolutional Gated Linear Unit(CGLU)[2]模块,提出了一种轻量化卷积网络结构。在降低计算复杂度的同时,该结构显著提升了模型对高宽比植物幼苗的识别能力。为进一步增强特征提取效果,模型引入 WaveletPool[3] 替代传统的池化操作,从而更有效地保留空间结构信息。
本项目系统性地设计了数据增强策略、优化训练流程,并针对网络结构进行了多项改进,使模型在多个评价指标上均取得了优异表现,展现出良好的实用性与泛化能力。此外,基于该改进模型,项目采用 PyQt 框架开发了一款植物幼苗图像分类的桌面应用,实现了高效便捷的图像分类功能。
This project aims to develop a high-performance deep learning model for plant seedling image classification tasks. Based on the improved YOLO11m-cls architecture, the proposed lightweight convolutional network structure integrates the StripBlock and Convolutional Gated Linear Unit (CGLU) modules. This design not only reduces computational complexity but also significantly enhances the model's ability to recognize high aspect ratio plant seedlings. To further improve feature extraction, the model introduces WaveletPool as a replacement for traditional pooling operations, effectively preserving spatial structure information.
The project systematically designs data augmentation strategies, optimizes the training process, and incorporates multiple improvements to the network architecture. As a result, the model achieves outstanding performance across various evaluation metrics, demonstrating strong practicality and generalization capabilities. Moreover, leveraging the improved model, a desktop application for plant seedling image classification was developed using the PyQt framework, providing an efficient and user-friendly image classification solution.
2. 介绍
计算机视觉是人工智能领域中发展迅速的分支之一,旨在赋予机器理解和解释视觉信息的能力。其中,目标检测作为计算机视觉的重要研究方向,涉及在图像或视频流中精确地识别并定位特定目标。近年来,随着深度学习技术的飞速发展,目标检测算法在准确率与效率上都取得了显著突破。
目标检测领域的一个里程碑是 Redmon 等人于 2015 年提出的 "You Only Look Once" (YOLO) 算法。YOLO 的核心思想是将目标检测任务简化为单阶段的回归问题,通过单一的卷积神经网络直接预测图像中的边界框和类别概率,大幅提升了检测速度与实时处理能力。这一创新架构颠覆了传统的两阶段检测流程(如 R-CNN 系列),使得目标检测能够更高效地应用于实际场景中。
作为 YOLO 系列的最新版本,YOLOv11[4] 于 2024 年的 YOLO Vision 2024 (YV24) 大会中正式发布,标志着实时目标检测技术的又一次跨越。YOLOv11 在网络架构、特征提取和优化策略方面进行了全方位改进:不仅引入了更高效的特征金字塔网络,还优化了多尺度检测机制,进一步提升了对细粒度目标的识别能力。此外,YOLOv11 通过新的注意力机制与轻量化模块的引入,实现了更快的推理速度和更低的计算成本。
尽管 YOLOv11 在实时检测任务中表现出色,但其对高宽比目标(例如植物幼苗)检测的能力仍有改进空间。为此,本项目基于 YOLOv11m-cls 架构,提出了一种改进型的轻量化卷积网络结构,结合了 StripBlock 和 Convolutional Gated Linear Unit (CGLU) 模块,以更好地适应高宽比植物幼苗的特征表达。与此同时,我们引入 WaveletPool 作为替代传统上/下采样的机制,从而更有效地保留空间结构信息,增强模型对复杂边缘和细节特征的捕捉能力。
3. 相关工作
3.1 使用 YOLO 模型的目标检测
目标检测是计算机视觉中的核心任务,旨在识别图像或视频中的所有目标并准确预测其边界位置与类别信息。自 You Only Look Once (YOLO) 于 2015 年被提出以来,凭借其单阶段检测架构,显著加速了检测速度并简化了模型设计。传统的两阶段方法(如 R-CNN 系列)通常需要先生成候选区域再进行分类与定位,而 YOLO 通过单一的卷积神经网络(CNN)直接回归目标的边界框与类别,实现了端到端的目标检测。
尽管 YOLO 系列在检测速度和精度方面取得了重大突破,但对于 高宽比目标 的检测表现仍存在提升空间。植物幼苗在自然生长环境下,其叶片和茎秆常表现出细长的高宽比特征,并且容易受到背景干扰和遮挡的影响 [6]。传统的 YOLO 架构使用固定大小的卷积核和特征图分辨率,对这类不规则目标的边缘和形态难以精确捕捉。
3.2 注意力机制改进
在深度学习模型追求高性能的同时,计算资源和推理效率成为重要考量。传统的大型卷积神经网络尽管在目标检测与分类任务中表现出色,但其高昂的计算代价使得实际部署受限。近年来,轻量化卷积网络的研究逐渐兴起,其中 MobileNet 和 EfficientNet 是典型代表。
MobileNet 采用深度可分离卷积 (Depthwise Separable Convolution),将标准卷积拆分为逐通道的深度卷积与逐像素的逐点卷积,显著减少了计算复杂度。
EfficientNet 提出复合缩放策略,通过同步调整网络的宽度、深度和分辨率,以最小的计算开销获得最大化的性能提升。
尽管这些轻量化网络在参数量和推理速度上都有显著改进,但对于特定形态(如高宽比明显的植物幼苗)的特征捕捉仍存在不足。因此,本项目设计并引入了 StripBlock 和 Convolutional Gated Linear Unit (CGLU) 模块,以进一步优化网络对细长目标的表达能力,并在轻量化的基础上保持高精度检测。
3.3 池化方法
池化(Pooling)是卷积神经网络中常用的下采样操作,旨在减少特征图的空间维度,从而降低计算复杂度并抑制噪声。传统的最大池化 (Max Pooling) 和平均池化 (Average Pooling) 是最常见的池化方式,分别取局部窗口的最大值或平均值作为下采样后的特征值。然而,这种基于固定窗口的采样策略往往忽略了局部细节,导致空间信息的丢失,尤其对包含精细边缘特征的目标表现不佳。
为缓解这一问题,近年来提出了多种改进方案,例如 Spatial Pyramid Pooling Network (SPPNet) 和 Atrous Spatial Pyramid Pooling (ASPP) 。SPPNet 通过在不同尺度下对特征图进行池化,生成多层次的特征表示,从而更好地捕捉不同大小目标的特征;ASPP 则基于扩张卷积 (Dilated Convolution) 构建多尺度感知域,有效提升了分割任务中的边缘捕捉能力。然而,这些方法虽然改善了多尺度特征表达,但在下采样过程中仍未能完全避免空间信息的丢失。
为解决上述问题,本项目提出引入 WaveletPool 作为替代传统池化方式的策略。WaveletPool 基于小波变换的多尺度分解特性,将特征图分解为不同频率分量:低频部分保留主要的全局特征信息,而高频部分则捕捉细节与边缘特征。相比于最大池化和平均池化直接丢弃部分信息的方式,小波池化通过频域表示更好地保留了空间结构,从而提升了对复杂形态目标(如植物幼苗叶片边缘)的检测效果。
实验结果表明,WaveletPool 在植物幼苗图像分类任务中表现出色,尤其在高宽比显著、边缘复杂的目标检测上,显著减少了边缘模糊与形态断裂的问题,提升了模型的分类精度和特征表达能力。改进后的网络不仅在空间结构保持上优于传统方法,也在推理速度上保持高效,实现了更优的检测性能。
3.4 植物幼苗分类
植物幼苗分类是农业信息化与智能种植领域的重要研究方向,其目的是对不同品种和生长状态的幼苗进行精确识别与分类。这一任务的核心挑战在于,植物幼苗通常呈现复杂的形态结构,且生长环境多变,包括光照强度、土壤背景以及遮挡情况等因素都会对图像处理产生干扰。传统的基于手工特征的方法(如颜色、纹理和形状分析)虽然在一定程度上能够区分不同幼苗种类,但在面对复杂背景和高宽比显著变化的目标时表现出明显的局限性。
近年来,深度学习技术的引入显著提升了植物幼苗分类的精度与鲁棒性。基于卷积神经网络的模型能够自动提取多层次的特征表达,减少对人工特征设计的依赖。例如,有研究使用 ResNet 或采用 EfficientNet 等架构对植物幼苗进行分类。然而,这些方法主要集中在整体目标的分类,对于植物幼苗这一具有高宽比且结构细长的目标检测仍存在瓶颈。
针对上述问题,本项目基于 YOLO11m-cls 构建了一种改进型的轻量化卷积网络,专门针对高宽比植物幼苗的检测与分类任务进行优化。
4. 研究
本项目提出了一种改进型轻量化卷积网络结构,旨在提升植物幼苗图像分类的性能。该方法基于 YOLO11m-cls 模型,通过引入 StripBlock 和 Convolutional Gated Linear Unit (CGLU) 模块优化网络对高宽比目标的特征提取能力,同时结合 WaveletPool 替代传统池化操作以保留图像的空间结构信息。整个模型架构经过精心设计,以实现高效、准确的植物幼苗分类。
4.1 模型架构设计
基于经典 YOLO11m-cls 网络进行训练后,尽管整体性能达到了较为理想的水平,但在处理部分数据样本(尤其是高宽比目标)时,仍存在识别准确率不高的现象。通过采用 Grad-CAM++[5] 对模型的注意区域进行可视化分析,发现这两类目标在图像中的主要特征均表现为细长型叶片,具有较高的外观相似性,导致模型难以准确区分。
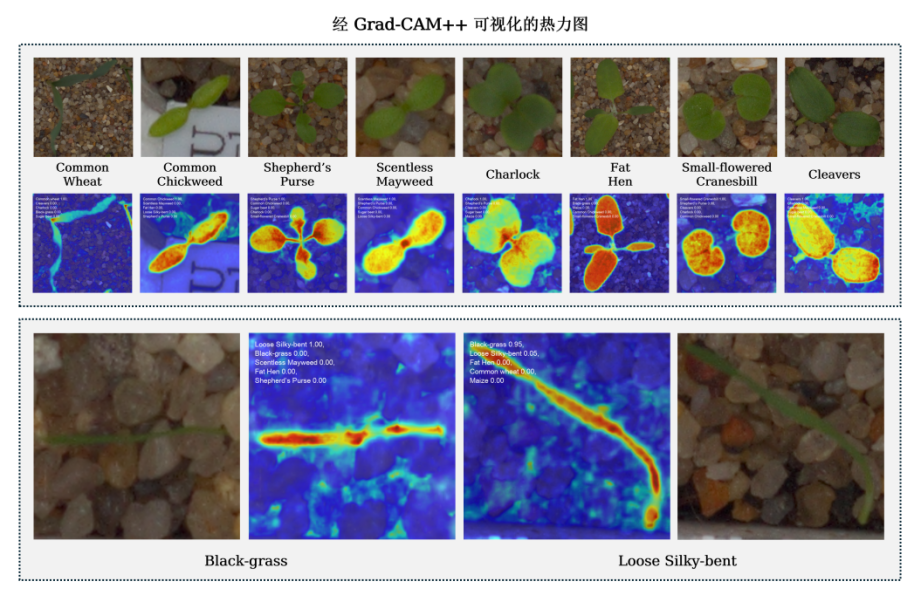
为进一步提升模型对这类目标的检测与分类能力,项目在 YOLO11m 网络结构基础上提出了如下两项结构性改进。
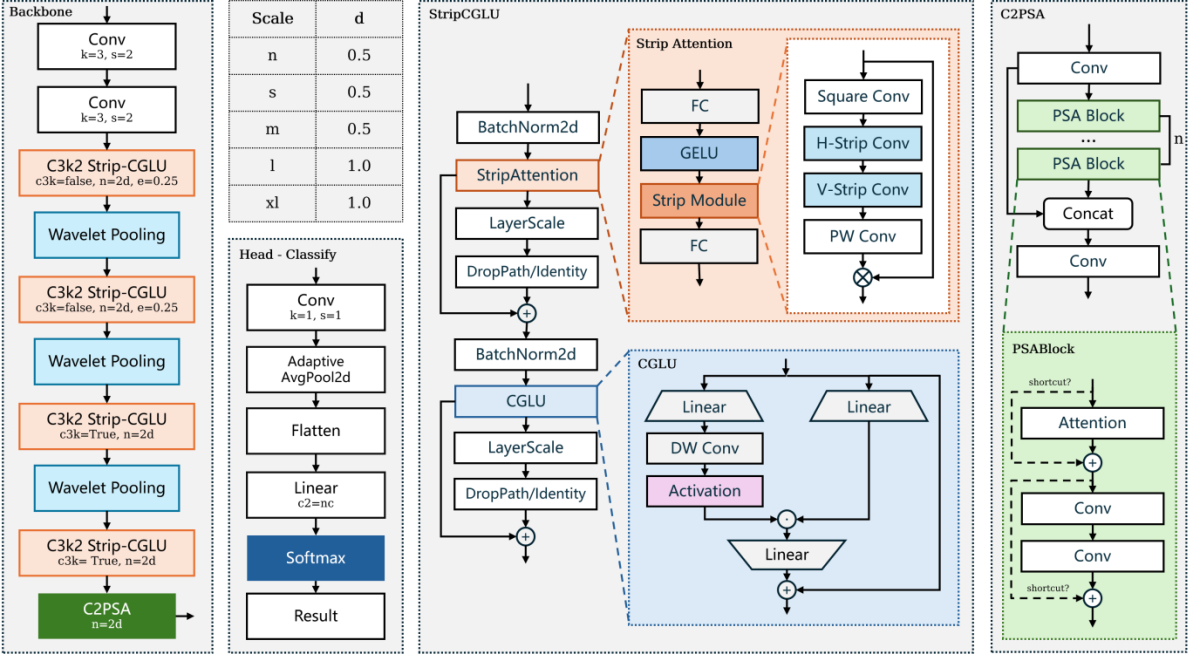
4.1.1 引入 StripBlock 增强对高宽高比目标的特征提取能力
项目使用的数据集中包含大量细长植物叶片结构,即具有高宽比特征的目标。然而,YOLO 系列模型在处理此类目标时效果较差,模型的检测性能通常随着目标宽高比的增加而下降。
高宽比目标在其主轴方向上包含较为丰富的语义信息,而在正交方向上特征较为稀疏。传统 CNN 模块基于方形卷积核提取局部信息,难以充分捕捉细长目标的主轴方向特征,且容易引入冗余背景信息。为此,项目引入 Strip-R CNN 提出的 StripBlock 模块,并融合 Convolutional Gated Linear Unit(C-GLU)结构对原 YOLO11 网络中的 C3k2 模块进行重构,以提升模型对高宽比目标的感知能力。
StripBlock 提出了一种轻量级的条带卷积序列结构,可在保留局部细节的同时,增强对细长方向结构的感知能力。其核心结构如下所示:
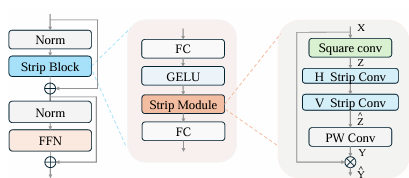
假设输入特征图\mathbf{X}\in\mathbb{R}^{C\times H\times W},首先应用一次深度可分离卷积,卷积核为\mathbf{K}\in\mathbb{R}^{C\times k_{H}\times k_{W}} ,提取局部上下文信息并得到中间特征图 \mathbf{Z}。
随后,依次施加两个方向上的条带卷积:首先是高度为 H、宽度较小的垂直卷积核,接着是宽度为 W的水平卷积核,以便充分提取细长结构沿不同主轴方向的连续特征。输出记作\hat{\mathbf{Z}} 。
接着应用1\times1点卷积增强通道维度上的信息交互,输出特征图为\mathbf{Y}。将其作为注意力图与输入特征图\mathbf{X}进行逐元素加权,得到最终输出\hat{\mathbf{Y}}=\mathbf{X}\cdot\mathbf{Y},从而实现基于方向感知注意力的特征重构。
class Strip_Block(nn.Module):
def __init__(self, dim, k1, k2):
super().__init__()
self.conv0 = nn.Conv2d(dim, dim, 5, padding=2, groups=dim)
self.conv_spatial1 = nn.Conv2d(dim,dim,kernel_size=(k1, k2), stride=1, padding=(k1//2, k2//2), groups=dim)
self.conv_spatial2 = nn.Conv2d(dim,dim,kernel_size=(k2, k1), stride=1, padding=(k2//2, k1//2), groups=dim)
self.conv1 = nn.Conv2d(dim, dim, 1)
def forward(self, x):
attn = self.conv0(x)
attn = self.conv_spatial1(attn)
attn = self.conv_spatial2(attn)
attn = self.conv1(attn)
return x * attn4.1.2 引入 ConvGLU 结合 C3k2 增强通道间特征的非线性交互能力
此外,项目引入 Convolutional Gated Linear Unit(ConvGLU),进一步增强通道间特征的非线性交互能力。相较于传统 SE 机制或多层感知机,GLU 在多种任务中显示出更优的建模能力。其核心思想是:将输入特征进行两路线性映射,其中一支通过激活函数生成门控信号,两路输出按元素逐位相乘,从而实现信息的有选择性传递。
为提高空间感知能力,项目引入 ConvGLU 的改进结构,在 GLU 的门控分支中引入轻量级的深度可分离卷积核,使其具备基于局部邻域的通道注意力能力。相比于 SE 中基于全局平均池化生成的粗粒度门控信号,ConvGLU 为每个位置提供独立的、基于近邻特征的精细化控制信号,提升了模型对局部结构和空间位置的敏感性。
CGLU 主要由输入的线性变换、深度卷积、激活函数以及元素相乘等操作构成。首先,输入数据会经过两个不同的线性变换分支,一个分支产生的结果(记为分支一结果)会直接用于后续计算,另一个分支产生的结果(记为分支二结果)会先进行 3×3 深度卷积操作,然后通过 GELU 激活函数进行激活。之后,激活后的分支二结果与分支一结果进行元素相乘,最终得到 Convolutional GLU 的输出。这种结构设计使得它能够利用深度卷积提取的局部特征信息来调整门控信号,从而实现基于最近邻特征的门控通道注意力机制,有效提升模型性能。
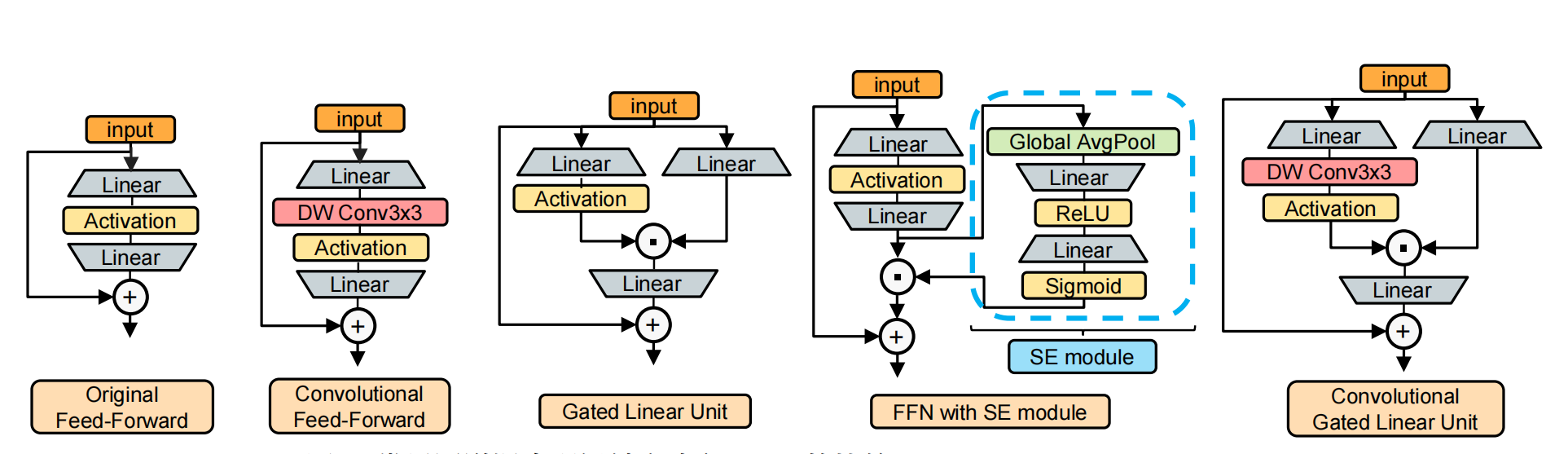
ConvGLU 的门控分支结构如下所示:
其中,\mathbf{X}为输入特征图, \mathbf{W}_v和 \mathbf{W}_g分别为值分支与门控分支的线性权重,DWConv表示深度卷积,Act(\cdot) 为激活函数,\odot表示逐元素乘法。
此外,ConvGLU 的计算复杂度相较于传统的卷积前馈网络(ConvFFN)更低。在相同扩展比和卷积核尺寸 下,ConvGLU 的计算复杂度低于 ConvFFN。因此,ConvGLU 在保持模型容量基本不变的情况下,提高了模型的表达能力与空间建模能力,适用于需要位置感知能力的特征提取场景。
通过将 ConvGLU 与 StripBlock 结构结合构建改进的 C3k2 模块,项目进一步增强了模型对高宽比目标及其局部区域的表达与分类能力,提升了植物幼苗检测分类的准确性。
class ConvolutionalGLU(nn.Module):
def __init__(self, in_features, hidden_features=None, out_features=None, act_layer=nn.GELU, drop=0.) -> None:
super().__init__()
out_features = out_features or in_features
hidden_features = hidden_features or in_features
hidden_features = int(2 * hidden_features / 3)
self.fc1 = nn.Conv2d(in_features, hidden_features * 2, 1)
self.dwconv = nn.Sequential(
nn.Conv2d(hidden_features, hidden_features, kernel_size=3, stride=1, padding=1, bias=True, groups=hidden_features),
act_layer()
)
self.fc2 = nn.Conv2d(hidden_features, out_features, 1)
self.drop = nn.Dropout(drop)
def forward(self, x):
x_shortcut = x
x, v = self.fc1(x).chunk(2, dim=1)
x = self.dwconv(x) * v
x = self.drop(x)
x = self.fc2(x)
x = self.drop(x)
return x_shortcut + x4.1.3 引入 Wavelet 池化
Wavelet Pooling 是一种用于卷积神经网络中的新型池化方法,旨在改进传统池化技术如最大池化和平均池化的局限性。与传统池化方法仅保留局部最大或平均值不同,Wavelet Pooling 通过小波变换将特征图分解为不同频率的子带(即 LL、LH、HL 和 HH),从而在压缩图像信息的同时更好地保留边缘、纹理等高频细节信息。
在本项目中,为提升 YOLO11 在植物幼苗检测任务中的空间特征保持能力和上下文理解能力,我们在其上采样和下采样阶段引入了 Wavelet Pooling 技术。
具体而言,在下采样阶段将传统的最大池化操作替换为离散小波变换(DWT)后,仅保留 LL 分量用于后续特征传递。这种方式在降低分辨率的同时,显著增强了网络对局部结构和边缘信息的保持能力,尤其适用于植物叶片纹理和边界较为复杂的图像区域。
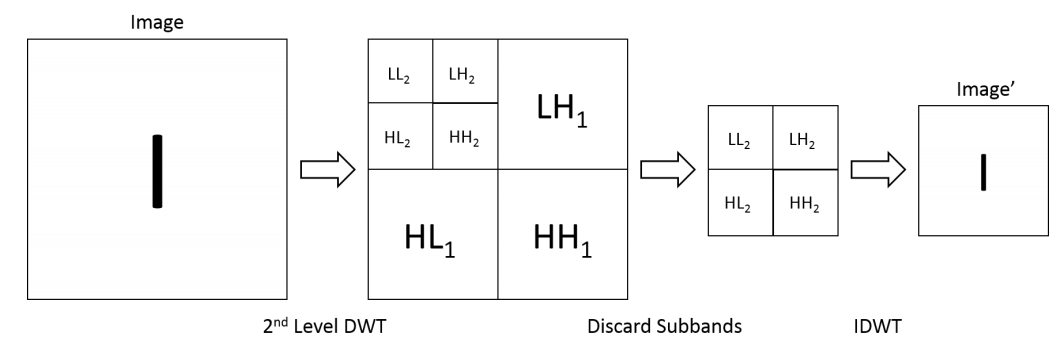
引入 Wavelet Pooling 后,模型在多个尺度上的信息融合能力得以增强,显著提升了特征金字塔中高层语义信息与底层细节信息的匹配程度。此外,通过小波分解与重构操作,网络具备了更强的频域建模能力,有助于提高在复杂背景下对植物幼苗的识别稳定性与泛化性能。
class WaveletPool(nn.Module):
def __init__(self):
super(WaveletPool, self).__init__()
ll = np.array([[0.5, 0.5], [0.5, 0.5]])
lh = np.array([[-0.5, -0.5], [0.5, 0.5]])
hl = np.array([[-0.5, 0.5], [-0.5, 0.5]])
hh = np.array([[0.5, -0.5], [-0.5, 0.5]])
filts = np.stack([ll[None,::-1,::-1], lh[None,::-1,::-1],
hl[None,::-1,::-1], hh[None,::-1,::-1]],
axis=0)
self.weight = nn.Parameter(
torch.tensor(filts).to(torch.get_default_dtype()),
requires_grad=False)
def forward(self, x):
C = x.shape[1]
filters = torch.cat([self.weight,] * C, dim=0)
y = F.conv2d(x, filters, groups=C, stride=2)
return y4.2 数据集与数据增强
项目使用来自 Kaggle 的公开数据集 Plant Seedlings Classification,包含 12 种共 5539 张植物幼苗图像。为保证模型训练过程中的性能评估客观有效,项目按照 7:2:1 的比例对原始数据集进行划分,分别构建了训练集、验证集与测试集。

为了提高模型的泛化能力、降低过拟合的风险,本项目引入了 Albumentations 图像增强库对训练数据进行多样化处理。与 Ultralytics YOLO 所提供的内置数据增强方法(如随机翻转、色彩调整等)相比,Albumentations 不仅支持基本的图像增强操作,还提供了更高级的空间变换(如透视变换、旋转裁剪等)和混合增强(如 Overlay Elements、MixUp 等),能够模拟更多真实环境下的图像变化,从而增强模型在复杂场景中的表现。
在项目模型的实际训练过程中,结合使用 Albumentations 的几种典型增强策略,如随机缩放、亮度对比度调整、透视变换等,不仅丰富了训练样本的分布,还有效提升了模型对环境变化和图像扰动的适应性。

4.3 训练策略
考虑到本项目在 YOLO11 模型基础上对骨干网络进行了定制优化,为确保模型权重与网络结构完全一致,训练过程中采用从零训练策略。训练过程中,模型采用了 SGD 优化器。为了避免过拟合,使用了 Dropout 和 Early Stopping 技术。训练过程中,我们采用了 K-Fold Cross-Validation 方法来评估模型的泛化能力,确保在不同数据集上都能得到稳定的性能。
4.4 评估指标
针对分类任务,模型的性能评估不仅依赖于整体准确率,还需引入更加细致和多角度的评价指标,以全面反映模型的判别能力。本项目采用 Top-K 准确率和混淆矩阵作为主要的分类性能评估手段。
Top-K 准确率是多类别分类任务中常用的一种评估方式,其中 Top-1 准确率即为传统意义上的分类准确率,表示模型预测的第一候选类别与真实类别相同的比例。Top-K 准确率则进一步扩展了这一概念,表示真实类别是否出现在模型预测概率最高的前 K 个类别中。这一指标尤其适用于类别较多或类别间相似度较高的任务场景,能够更好地反映模型对“接近正确”的分类结果的容忍性和实际应用价值。
其中\mathbb{1}(\cdot)是指示函数,当括号内条件为真时取 1,否则为 0。
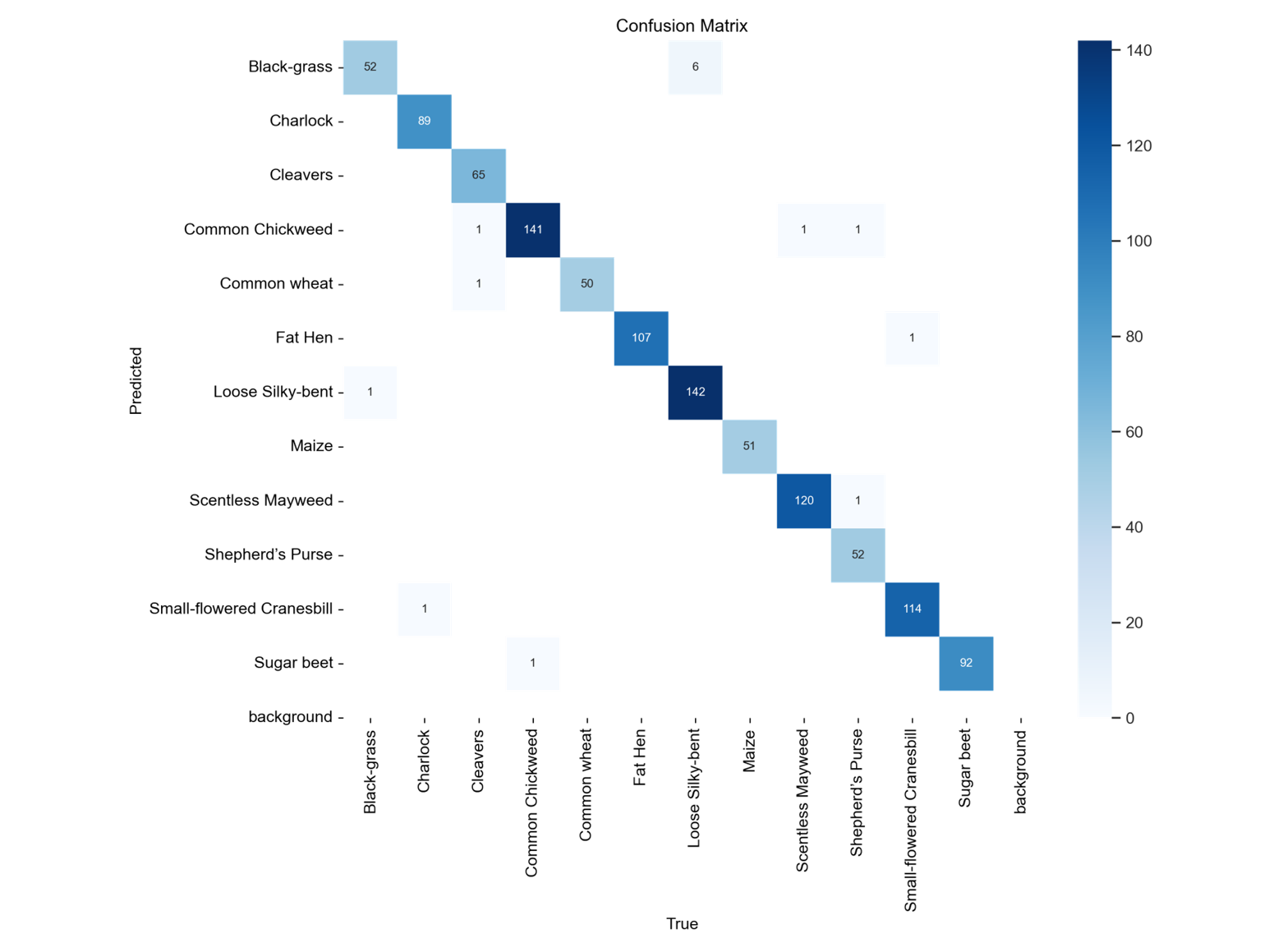
混淆矩阵则用于分析模型在各类别之间的具体分类表现。混淆矩阵以真实标签和预测标签的组合方式构建,通过矩阵中的对角线元素可以看出模型在各类别上的准确预测数量,而非对角线部分则揭示了模型在不同类别之间的误判关系。通过观察混淆矩阵,可以识别出哪些类别易被混淆,从而为后续的模型调整提供依据。
混淆矩阵还可用于计算精确率、召回率、F1 分数等更细粒度的评估指标,便于从不同维度分析模型性能。
其中:
TP_i为类别 的真正例数量(预测为i且真实为i );
FP_i为假正例(预测为i 但真实非i );
FN_i为假负例(预测非i 但真实为i )。
在本项目中,结合使用 Top-K 准确率和混淆矩阵。Top-K 准确率用于衡量整体的预测能力,而混淆矩阵则用于诊断模型在特定类别上的偏倚或弱点,从而指导模型结构优化与数据增强策略的改进。
5. 实验
5.1 消融实验设置
为验证以上所提出的各项改进对模型性能的具体贡献,项目以从零训练的原始 YOLO11m-cls 模型作为基线,设计并实施了一系列消融实验。
实验分别在引入 StripBlock 与 Convolutional GLU 改进 C3k2 模块和引入 Wavelet 池化的基础上,逐步叠加各模块以观察性能变化,从而分析各改进模块对整体检测准确率的影响。
5.2 实验结果
以上各实验模型在验证集上的 Top-1 Accuracy 与 Top-5 Accuracy 表现如下:
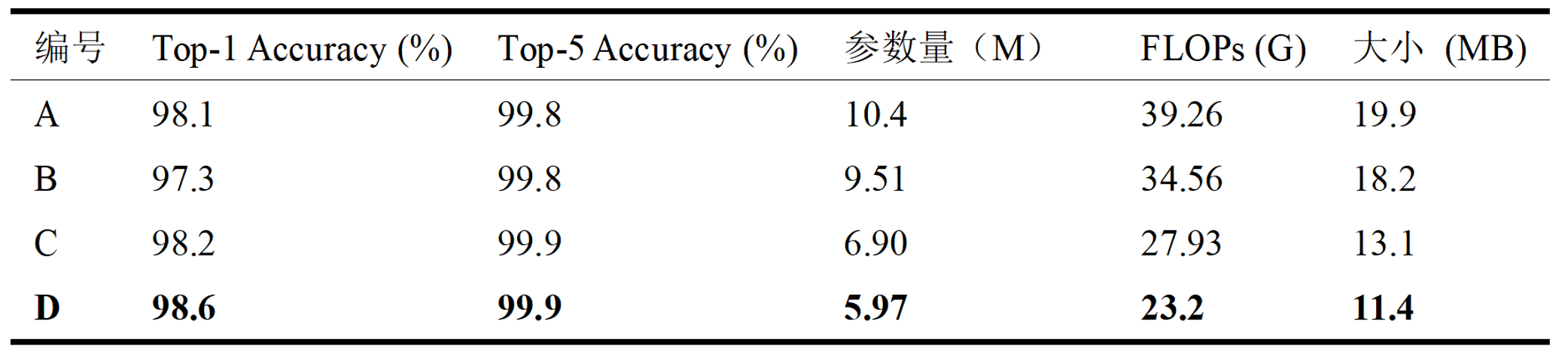
自消融实验结果表格中可以看出:
基线模型(A)作为参考标准,在 Top-1 Accuracy 上达到了 98.1%,Top-5 Accuracy 为 99.8%,表现稳健,但参数量和计算量相对较高。
模型 B(引入 StripBlock + ConvGLU 改进 C3k2)在 Top-5 Accuracy 上保持不变(99.8%),但 Top-1 Accuracy 略微下降至 97.3%。尽管该模块在特征提取能力上有所增强,但可能由于引入的门控机制导致模型在某些类别判别上产生不确定性,影响了整体 Top-1 表现。不过,模型参数量、FLOPs 以及模型大小均有所减少。
模型 C(引入 Wavelet Pooling 改进上下采样)提升了 Top-1 和 Top-5 Accuracy 至 98.2% 和 99.9%。同时,其在参数量(6.90M)、FLOPs(27.93G)和模型大小(13.1MB)方面均较模型 A 有明显下降,表明该结构能够有效保留空间信息,并提升模型性能的同时实现模型压缩。
模型 D(整合 StripBlock 与 Wavelet Pooling)达到了最高的 Top-1 Accuracy(98.6%)和 Top-5 Accuracy(99.9%),同时在参数量(5.97M)、FLOPs(23.2G)和模型大小(11.4MB)方面均为最优。这表明 StripBlock 与 Wavelet Pooling 在结构上具有良好的互补性,能够协同提升模型的表示能力与推理效率。
综上所述,项目提出的结构改进方案在不牺牲准确率的前提下,提升了模型的参数效率和计算效率,特别适用于资源受限场景下的植物幼苗识别任务。
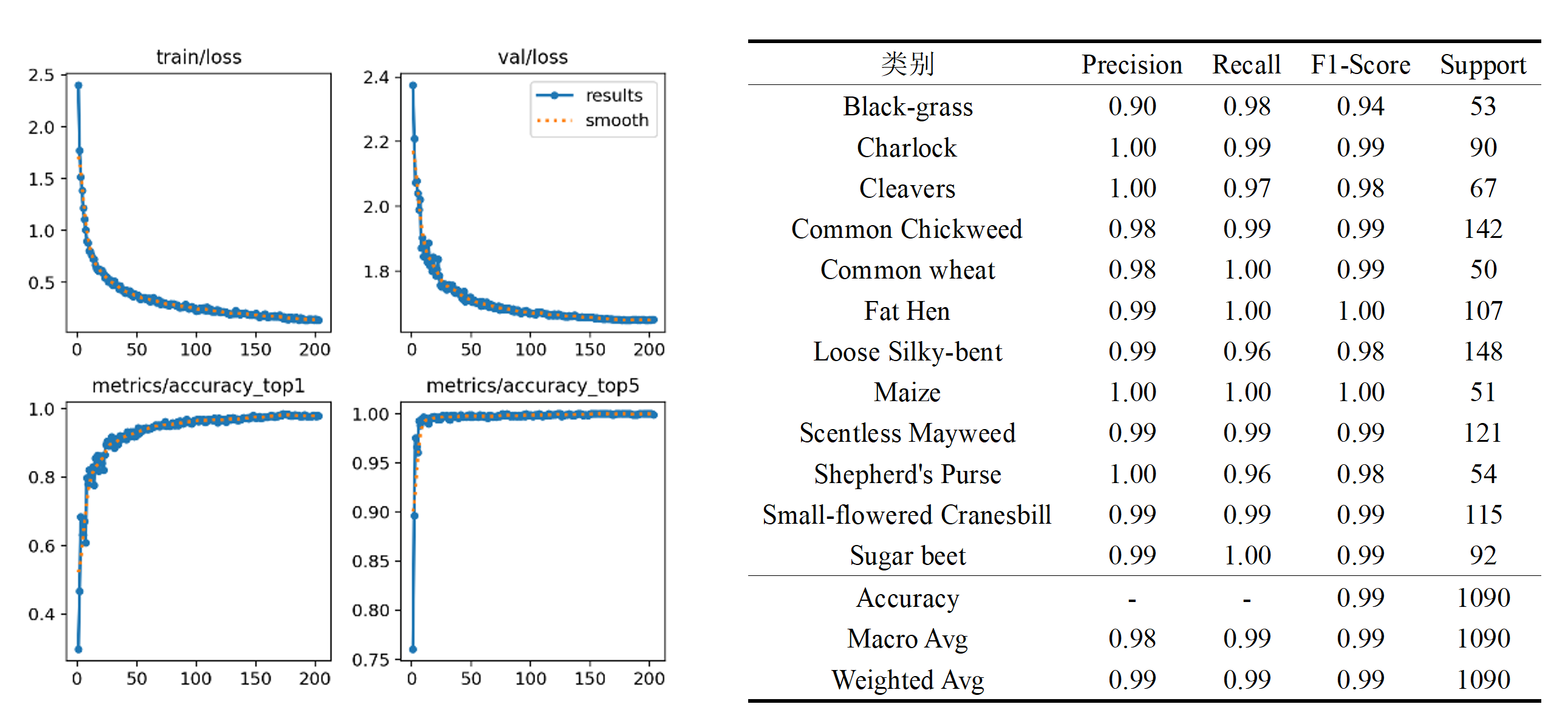
其中,编号 D 模型的相关指标如下:
6. 系统设计与实现
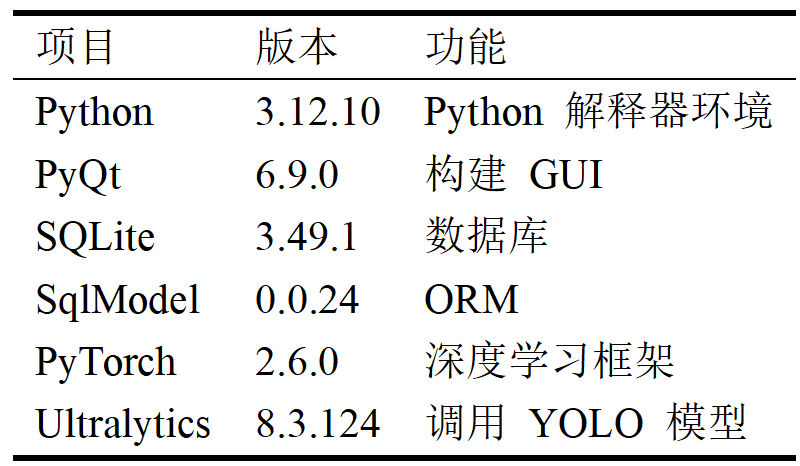
本项目基于改进后的 YOLO11 模型,采用 Python 3.12 作为开发语言,结合 PyQt 框架实现图形用户界面。项目核心技术栈如下所示:
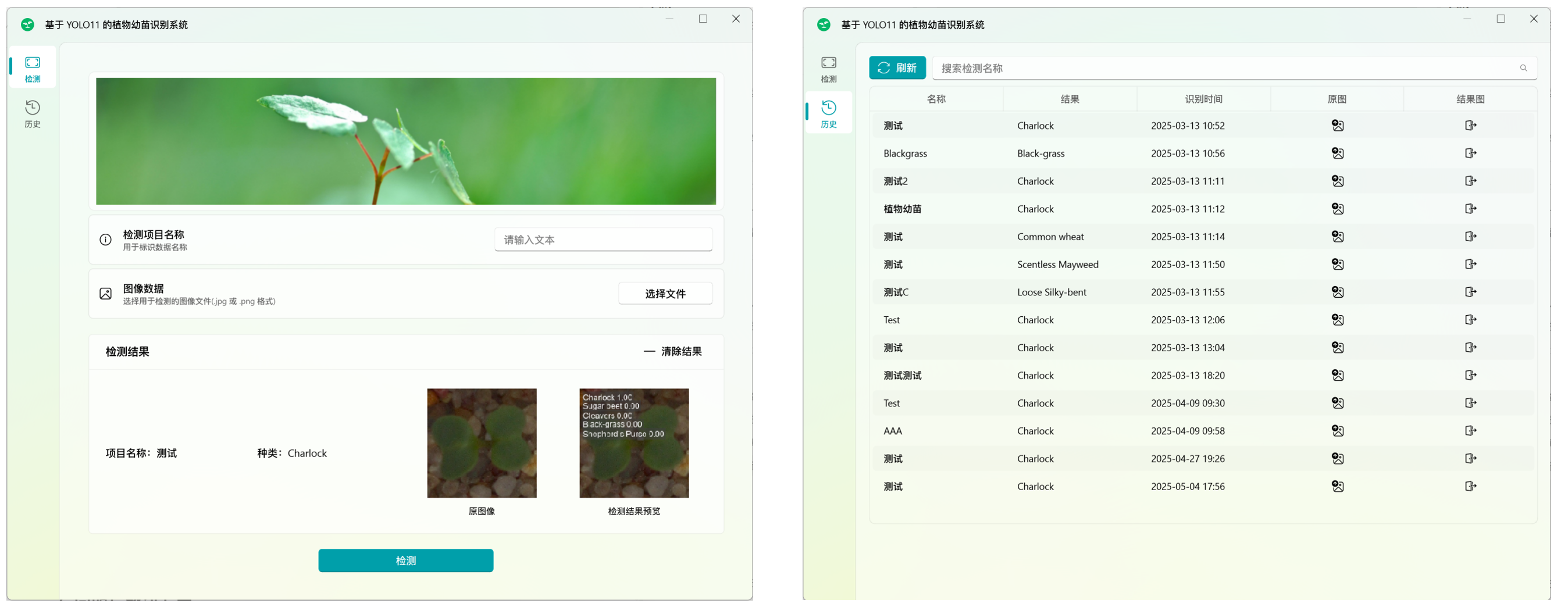
本项目实现的植物幼苗识别系统包含两个核心功能模块:检测页面与检测历史记录页面。
检测页面:提供图像上传与检测功能,支持用户通过加载本地图像进行植物幼苗识别,检测结果以图形化方式显示,并提供对应的识别结果。
检测历史页面:用于展示用户历史检测记录,包含检测时间、图像缩略图、识别结果等信息,支持按时间或结果筛选、查看详细检测报告等操作。
7. 结论
本项目以植物幼苗图像分类任务为研究背景,基于YOLO11架构并融合StripBlock与 Convolutional GLU模块,提出了改进的YOLO11 + StripCGLU + WaveletPool 网络结构。在模型训练过程中,采用了从零训练策略,并引入 Albumentations 数据增强方案,有效提升了模型的泛化能力与对复杂场景的鲁棒性。
通过引入针对细长目标的方向感知模块 StripBlock 和通道注意力增强机制 ConvGLU,改进后的模型在 Top-1 与 Top-5 准确率上均优于原始YOLO11模型,特别是在对高宽比植物结构的识别中展现出显著优势。同时,基于混淆矩阵分析和 GradCam++ 可视化结果进一步优化了模型在易混类别上的表现。项目的完整训练流程、自定义模块设计与评估指标体系均经过验证,证明了本方法在针对植物幼苗分类任务中的可行性和有效性。
8. 参考文献
[1] Yuan, X., Zheng, Z., Li, Y., Liu, X., Liu, L., Li, X., Hou, Q., & Cheng, M.-M. (2025). Strip R-CNN: Large Strip Convolution for Remote Sensing Object Detection. https://arxiv.org/abs/2501.03775
[2] Shi, D. (2024). TransNeXt: Robust Foveal Visual Perception for Vision Transformers. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 17773–17783.
[3] Williams, T., & Li, R. (2018). Wavelet Pooling for Convolutional Neural Networks. International Conference on Learning Representations. https://openreview.net/forum?id=rkhlb8lCZ
[4] Jocher, G., & Qiu, J. (2024). Ultralytics YOLO11 (11.0.0) [Computer software]. https://github.com/ultralytics/ultralytics
[5] Chattopadhyay, A., Sarkar, A., Howlader, P., & Balasubramanian, V. N. (2017). Grad-CAM++: Generalized Gradient-based Visual Explanations for Deep Convolutional Networks. ArXiv Preprint ArXiv:1710.11063.