
.jpg)
前言
最近终于从这半年的考研模式里抽身出来,开始慢慢恢复写代码、看论文的节奏。重新坐回 IDE 前的那几天,还是感觉很不适应:一方面是手感稍显生疏,另一方面,是我发现整个 AI 编程生态已经和半年前完全不是一回事了。
和 2025 年上半年相比,无论是模型能力,还是围绕模型构建的一整套 Agent 工具链,都发生了非常明显的变化。这种变化大到让我不得不认真思考:是不是应该把它们系统性地引入到自己的工作流中,而不是继续像以前那样“能不用就不用”。
以前,我对在正式项目中使用 AI 一直是比较克制的。在 AI IDE 刚出现的时候,我第一时间就下载尝试,而当时的体验确实相当不好。最典型的问题就是上下文长度不足。在旧的模型和工具条件下,只要项目稍微大一点,AI 就很容易失忆:它可能完全忽略已有的模块划分,凭空捏造不存在的接口,或者在你已经确定的架构上强行塞进一套新的逻辑。你一边让它写,一边还要不停地纠错、补上下文、解释“这里已经有实现了”“这个类型不是这么定义的”。那种感觉,与其说是协作,不如说是在给一个非常健忘的 partner 擦屁股。
在那种情况下,维护上下文本身就成了一种额外负担,远远抵消了它在敲代码层面带来的那点速度提升。所以那时我更愿意自己把控整体逻辑,AI 只偶尔用来查语法、补模板。
但这次回来之后,我的感受变了:不感叹不行,真是士别三日,当刮目相看。
在试用了几天 Claude Code、Codex 和 Gemini CLI 之后,我发现:现在的 Agent,已经不太像一个补全工具 Pro Max,而更像是一个能听懂约束、会按规则行事的协作者。这种变化并不只是上下文窗口变大这么简单,而是模型在理解复杂指令、遵循规则、配合工具方面,整体能力都上了一个台阶。
在不断尝试的过程中,一种更适合沉浸式编码的方式自然而然地出现了:不再执着于“我来写每一行代码”,而是把更多精力放在我想要什么结果、这个结果应该满足什么约束上。
这篇文章就是对我这段时间实践的一次整理:我如何理解 Vibe Coding 的变化,它在工程里到底解决了什么问题,又有哪些地方依然需要保持警惕。
最重要的:给 Agent 带上镣铐
这一个多月,我是把 AI 工作流渐进式地引入自己的学习和项目里的。
在这个过程中,我逐渐意识到一件事:在2026年,Vibe Coding 的核心,其实已经变了。
以前我们聊 AI 编程,更多是在讨论“它能不能快点把代码写出来”“能不能少敲点样板代码”。但现在,真正决定体验好坏的,已经不是生成速度,而是表达是否明确,对AI约束的是否清晰:也就是说,要让 Agent 带着镣铐跳舞。
在我现在的实践里,Agent 的行为主要由两层规则来限制:全局 AGENTS.md,用来规定 Agent 要遵守的基本规则;项目级的 AGENTS.md,用来补充或覆盖具体约定。
下面是我的全局 AGENTS.md,这些规则像是一种协议:哪些语言可以用、哪些库允许引入、代码风格如何、什么情况下必须停下来询问、什么情况下可以直接修改文件……都在这里规定,让 AI 强制遵守。
本指南适用于仓库全部目录,除非子目录另有 AGENTS.md 覆盖。
所有沟通全部使用中文、所有的代码注释、文档全部使用英文(并且只写关键部分的注释),新文件使用 UTF-8(无 BOM)。
禁用一切 CI/CD 自动化;构建、测试、发布必须人工操作。
在首次调用和每次上下文压缩之后,激活当前文件夹的 serena 项目,并在编码过程中需要进行语义查询或者符号搜索时,调用 serena。
编码前必须先使用 Sequential-Thinking 进行分析,然后采用 shrimp-task-manager 规划工作流程,确保变更边界最小并可审计。
获取 API 帮助信息优先使用 context7 查询 API 文档。 获取最新信息优先使用 exa 工具。
主动清理过时代码、接口、文档;如无迁移需求需说明“无迁移,直接替换”。
回复格式必须:
在开头提供【前置说明】(简要说明:本次任务、假设、是否调用工具等)。
若有工具/MCP/外部调用,在结尾提供【工具调用简报】(列出用过哪些工具、用途和结论)。
缩进根据当前文件编码风格决定使用 1 个 tab 还是用 4 个空格,默认使用 4 个空格。一旦规则写清楚了,很多之前让我头疼的问题会自然消失。我不用再反复确认它是不是在用过时的接口,也不用担心它突然写出一段完全不符合项目风格的代码。因为这些行为在规则层面就已经被堵死了。
这种体验带来的最大变化是:我可以把注意力从具体语法、细枝末节的实现中抽离出来,把更多精力放在逻辑推演和整体结构上。
这就让我产生了一种很强烈的回归感:不是回到写更多代码,而是回到了真正做工程设计这件事本身。
角色转变:人人都是技术架构师
当我开始稳定地使用 Code Agent 之后,另一个很直观的感受是:我的角色正在从“写代码的人”,转向“带着一支技术团队做工程的人”。
如果把一个 Code Agent 看作一名合格的研发工程师,那么现在流行的多 Agent 使用方式,本质上就是一个人同时领导着一个小型研发团队。在这种模式下,很多原本只存在于真实团队里的问题,会重新出现:如何分工、如何建立信任、如何评估产出。
在这里,信任的含义也发生了变化。它不再是人与人之间的情绪与共识,而是使用者是否真正了解工具的能力边界。只有清楚某个 Agent 擅长什么、不擅长什么,才能决定哪些任务可以放心交出去,哪些必须自己把控。
比如,我将项目规划和框架代码交给 Claude,文档和 UI 交给 Gemini,具体实现和修复 Bug 交给 Codex……(
没有说 Gemini 代码能力不好的意思,🐶)

我并不太关心 AI 的底层实现,而是通过持续的实际使用来判断它们的工程水平。不同工具在长期使用中,会自然呈现出非常鲜明的特征。有的在拆解任务和沟通方案上表现不错,但在复杂实现上容易偏离既定路线;有的整体节奏偏慢,但在修 Bug 和关键逻辑上更加稳定可靠。
这种判断并不是一开始就能得出的,而是通过不断试错和对比建立起来的。某种程度上,这和新人进入技术团队后的磨合过程非常相似。
在这个过程中,我也会刻意制造对比:把同样的需求和约束交给不同的 Agent,观察它们的实现质量和一致性。最终的分工完全基于结果:核心逻辑交给最稳定的 Agent,其余工具更多承担外围工作,比如文档、测试或界面整理。
这类虚拟团队有一个现实团队无法比拟的优势:代码可以无限重写,成本几乎为零,一切都可以围绕个人的技术审美来优化。代码本身不再稀缺,真正稀缺的是判断、审查和取舍的能力。
当然,这种分工并不是一成不变的。AI 工具的进化速度非常快,今天的结论在几个月后就可能失效。因此,与其给工具贴上永久标签,不如持续观察、持续调整,让它们在合适的位置上发挥作用。
从这个角度看,使用 Code Agent 并没有削弱工程能力,反而迫使我更清楚地思考:什么是核心问题,什么值得被自动化,而什么必须由人来决定。
上下文工程、提示词工程:回归到软件工程
很多人讨论 AI 编程时,都会把上下文工程当作关键因素,认为只要把上下文喂得足够完整,AI 生成代码的质量就会上去。对我来说,这个结论并不新鲜,反而有点似曾相识。
因为在人类工程实践里,我们早就遇到过同样的问题。多项目并行、频繁被打断、临时需求插队,本质上都是上下文过载。区别只是,人会通过文档、流程和工具,把上下文外包出去,而不是全靠大脑记忆。
这也是使用 AI Code 工具时非常自然的选择:把对话当成入口,把文档当成长期上下文。
在需求和技术细节明确之后,我会要求 AI 先生成结构化文档,后续所有实现都以文档为准,每推进一步就同步更新。这种方式本质上就是文档驱动或规范驱动开发,只不过现在的团队成员里,多了 AI。
当进入多 Agent 场景时,这一点变得更加重要。新的 Agent 实例,本质上就像新员工入职,而完善的文档和流程规范,能够让它快速完成 on-boarding,直接产出符合预期的代码。从这个角度看,所谓的 AI 工作流,其实是在用软件工程的老方法,解决新的协作对象。
我对 Vibe Coding 的态度也因此发生了变化。在流程规范、测试和约束足够扎实的前提下,我开始接受:部分低风险代码可以不逐行 review,而是通过文档、测试和自检来兜底。核心逻辑依然需要人工把控,但并不是所有代码都值得投入同样的精力。
这背后,其实是一个角色转换的问题。当你把自己当作这个虚拟技术团队的架构师时,代码不再是唯一的关注点,风险管理和效率平衡才是。
AI 工具当然无法为结果负责,但这本来就是架构师需要承担的部分。在 AI 时代,对程序员的要求并没有降低——如果不是通过亲手写代码来发现问题,那就必须具备足够的经验、嗅觉,或者问题定位和兜底能力。
如我在在文章开头所说,最终我越来越确信:AI 工作流的核心,并不是模型有多强,而是是否建立了一套稳定、可复用的上下文体系,让智能变得可控。
而这本来就属于软件工程的范畴。如此前读过的一本软件工程领域的经典《人月神话》所言:
概念完整性是系统设计中最重要的考虑因素。
工具在变,语言在变,甚至编写代码的主体都在变,但软件工程的核心挑战从未改变:就是如何在混乱与复杂中,通过清晰的约束,建立起那座概念完整的城堡。
从手写汇编到古法编程,我们该走向哪里?
没想到手写代码变成了古法编程……
编程的方式,一代代在变:从手写汇编的精细控制,到现在已成“古法”的手动模块化开发,再到今天 AI 工具辅助的开发流程。每一次变化都带来新的可能,也带来新的挑战。AI 时代,我们计算机专业的学生,该何去何从呢?
真的提效了吗?
最近有不少声音在说:AI 工具不仅没有提升效率,反而让效率变低了。对这个结论,我其实并不意外,也不觉得它是错的。
一方面,代码变得廉价,并不意味着成本消失了。生成成本降低,只是把工作量后移到了维护阶段。代码在项目里永远是负债,而不是资产,生成得越多,后续理解、排查和维护的心智负担就越重。
另一方面,AI 工具在成熟、复杂的项目里,很难一上来就发挥作用。真正让它提效,往往需要大量前置工作:流程梳理、环境打通、上下文补齐。而这些事情,本身就很费劲。
以我自己的几个项目环境为例,很多时候并不是AI 不够强,而是工作环境乱得不成样子:譬如对不上的 CUDA 版本、GCC 和 CMake 版本不匹配、老系统、无法升级的工具链、割裂的构建与开发环境,再叠加历史项目的各种祖传问题。在这种情况下,代码生成、构建、测试彼此脱节,AI 根本找不到一个稳定的切入点。
理论上,AI 在 Bug 排查、日志分析、问题复现上是非常有潜力的。但在老项目里,这些信息散落在各个角落,把上下文一点点粘起来的成本,常常已经抵消了自动化带来的收益。很多时候,还不如自己直接上手来得快。
所以我越来越觉得:AI 提效不是一个工具问题,而是一个工程成熟度问题。而一旦效率的问题不再只是“快不快”,一个更现实的问题自然就会出现:如果大量工作被提前自动化了,我们个人的成长,会不会反而被压缩?
在这成长,不如去那成长
一个常见担忧是:AI 会不会让人退化。如果只从写代码的手感来看,答案可能是肯定的。毕竟大量基础性工作正在被自动化,很多原本用于练手的路径,确实可能会消失。但我更倾向于认为,这不是成长被剥夺,而是成长的路径发生了迁移。
过去的成长,更多来自反复写实现;现在的成长,更多来自判断、取舍、排查和兜底。
所以,如果缺乏经验,就很容易被 AI 牵着走;但如果有足够的工程嗅觉,AI 反而会不断放大你的判断力。
这一年来,在 AI 的帮助下,我涉足了各个领域的编程:图形学、GLSL、深度学习、嵌入式等等等等,AI 并没有影响我学习新知识和新技术,反而为我扫清了相当多的障碍,让我能更专注与概念的理解和公式的推导上。
一句话说:自己本身对这个领域有足够的了解,才能较好地驾驭 AI。
但成长是一回事,感受又是另一回事。哪怕理性上知道路径在迁移,很多人依然会本能地问:当代码不再由我亲手写出来时,那种写代码的快乐,还在不在?
是解决问题带来了多巴胺,而不是写代码
我并不认同“AI 剥夺了写代码乐趣”这个说法。至少在我的业余项目里,恰恰相反。真正被转化的,是诸如 CRUD 之类的脏活累活。而真正留下来的,是我愿意亲手写的那部分代码。
架构师并不是不能写代码,而是可以选择写什么代码。把无聊的模块交出去,把自己最感兴趣、最有挑战的部分留下来,写代码的乐趣反而更纯粹了。
当然,和 AI 一起编程时,也确实更容易被打断心流。等待、打断、纠偏,本身就是一种消耗。这并不矛盾,只是不同阶段、不同任务的取舍。而当任务规模继续放大时,真正消耗人的,已经不再是写得累不累,而是:这些看似正确的实现,到底对不对。
此处是鞍点
在机器学习里,有一个很经典的概念,叫做鞍点。它看起来像是一个“已经不差”的位置:往某个方向走,Loss 在下降;但换个方向看,其实你正站在一个并不稳定、甚至相当糟糕的地方。
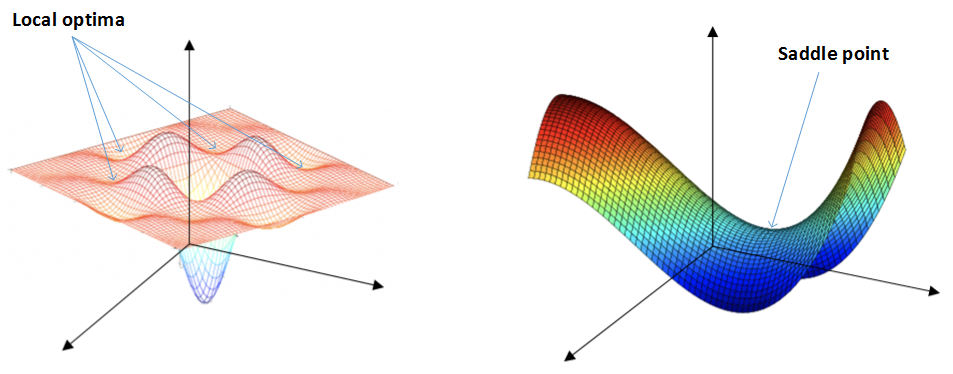
我越发觉得,复杂工程里的很多“正确”,本质上也是这种鞍点式的正确。单看某一段代码、某一个模块,它也许完全合理,甚至称得上优雅;但一旦把视角拉到整个系统层面,就会发现这些局部最优,正在悄悄把整体推向一个危险的位置。
目前的 AI Code Agent,在局部范围内已经非常强了,很多实现的准确率相当高。但工程真正难的地方,从来不在局部。老项目里那些隐藏逻辑、历史包袱和各种奇技淫巧的组合,不会出现在需求文档里,却真实地影响着系统行为。好的架构师要做的,不是追求每一段代码都看起来正确,而是让局部正确,尽可能接近全局正确。
这也是为什么我最近开始刻意放慢一些新功能的开发节奏,转而思考删减和整理。屎山不是一天形成的,但踩下刹车,往往要越早越好。
当我意识到这一点时,也慢慢想清楚了一件事:我们真正面对的转变,已经不是某个工具的出现,而是一种编程范式的迁移。
我们该走向哪里?
从手写汇编,到所谓“古法编程”,再到今天的 AI 工作流,技术一直在变,但有一点始终没变:复杂性不会消失,只会转移。
AI 不是让工程变简单了,而是把重心从“如何写”,推向了:如何管理、如何选择、如何兜底。
也许我们真正要走向的,并不是更快地写完代码,而是更清醒地做出决定:哪些事情值得自动化,哪些地方必须由人负责,以及:什么时候该停下来,把已经写出来的东西,好好整理一遍。
结语
《人月神话》里有一句话我一直很喜欢:There is no silver bullet.
三十多年过去,到了 AI 时代,它依旧没有过时。AI 让工具更强、效率更高,但复杂性不会凭空消失,责任也不会自动转移:它只是把问题从“如何把代码写出来”,推到了更难的层面:如何组织、如何权衡、如何在边界处兜底。
工具会放大我们的生产力,也会放大我们的判断力;它能帮我们跑得更快,却不能替我们看清方向,更不能替我们背负风险。真正的挑战,不是让模型多写几行,而是对复杂系统保持清醒的全局感:明确什么时候交给自动化,而什么时候必须亲手接管。
所以,工程师的价值,从来不只是“写代码的人”,而是“让系统安全、可控、高效运行的人”。AI 只是我们的助手,而方向与责任,仍在我们手中。
附录:Codex MCP 配置
最后记录一下我的 MCP 配置(已脱敏)。
model_provider = "right"
model = "gpt-5.2-codex"
model_reasoning_effort = "xhigh"
disable_response_storage = true
[features]
experimental_windows_sandbox = true
shell_snapshot = true
elevated_windows_sandbox = true
powershell_utf8 = true
[mcp_servers.sequential-thinking]
type = "stdio"
command = "npx"
args = ["-y", "@modelcontextprotocol/server-sequential-thinking"]
[mcp_servers.shrimp-task-manager]
type = "stdio"
command = "npx"
args = [
"-y",
"@mook_wy/mook-task-manager@latest",
"-e",
"DATA_DIR=.shrimp",
"-e",
"ENABLE_GUI=false",
"-e",
"TEMPLATES_USE=zh",
]
[mcp_servers.desktop-commander]
type = "stdio"
command = "npx"
args = ["-y", "@wonderwhy-er/desktop-commander@latest"]
[mcp_servers.exa]
type = "stdio"
command = "npx"
args = [
"-y",
"exa-mcp-server",
"tools=web_search_exa,get_code_context_exa,crawling_exa,company_research_exa,linkedin_search_exa,deep_researcher_start,deep_researcher_check",
]
[mcp_servers.exa.env]
EXA_API_KEY = "$$"
[mcp_servers.fetch]
type = "stdio"
command = "uvx"
args = ["mcp-server-fetch"]
[mcp_servers.context7]
type = "stdio"
command = "cmd"
args = [
"/c",
"npx",
"-y",
"@upstash/context7-mcp",
"--api-key",
"$$",
]
[mcp_servers.mcp-deepwiki]
type = "stdio"
command = "npx"
args = ["-y", "mcp-deepwiki@latest"]
startup_timeout_ms = 60000
[mcp_servers.ace-tool]
type = "stdio"
command = "cmd"
args = [
"/c",
"npx",
"ace-tool-rs",
"--base-url",
"$$",
"--token",
"$$",
]
[mcp_servers.ace-tool.env]
RUST_LOG = "info"